Idea
Where are several reasons for this test framework:
- We need to measure IO performance of our files at most of the ATLAS resources.
- We want to test impact of any changes we will make on: ROOT file organization/setting, ROOT/Athena version used, way we use the files.
- Need a way to compare different hardware, hardware and software site configurations. Optimize sites.
Access is open not only to ATLAS community but also ROOT and CMS collaborations. We are also open for communication with sites.
A short description of how stuff works underneath can be found
here.
HC side of things
There is a functional HammerCloud test set up which submits a test job to the most of large sites.
HummerCloud tries to always keep one test in the queue at ANALY queue of the sites. This usually means that sites run roughly 100 jobs per day. Tests are running continuously.
HC just submits the job using Ganga and there is no special settings, so we are seeing the same performance as any normal grid analysis job.
Whatever a site does for normal analysis job it does the same thing for the test jobs.
Tests
Each test job submited actually runs sequentialy several different IO tests. Some of them are:
- 10% no cache reads random sequential 10% of events with TTreeCache disabled.
- 10% default cache reads random sequential 10% of events with TTreeCache set to default value of 30MB.
- TOPJET should be a reasonably realistic TOPJET analysis code.
While the tests in this list are simple root scripts one has full freedom to execute whatever kind of test. One can for example download, install new ROOT version and run a script with it.
Results
Results are automatically uploaded to ORACLE database in CERN. The DB schema:
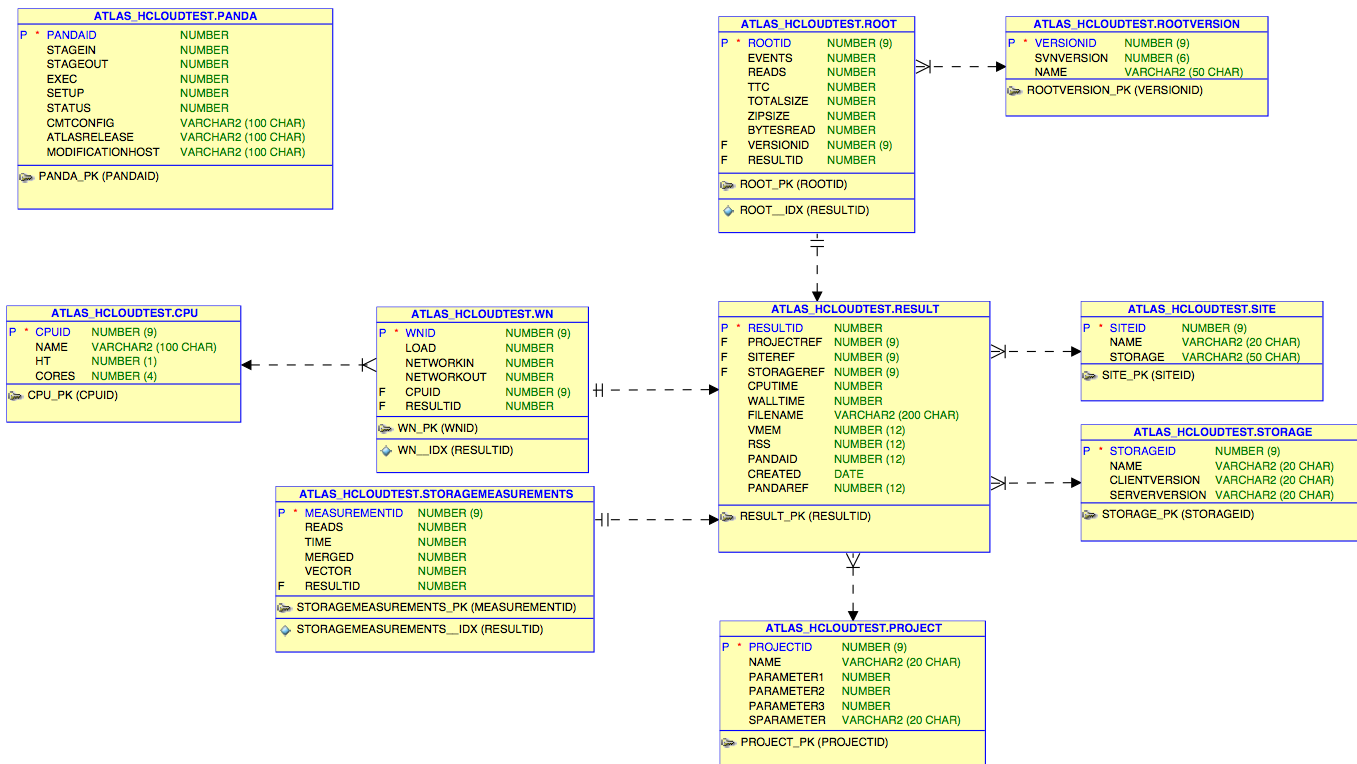
While the most of variables stored are self-explanatory I will try to find time to describe exactly how each of them is obtained.
For now it is important to explain content of the db table named "panda". HC test jobs collect pandaID. This ID is used by the cron job which runs every one hour to look up the pilot collected information from the panda monitor. From all of the panda monitor information we store: timing information (stage-in, stage-out, setup and exec times), job status, machine name, cmtconfig and atlas release. It is important to notice that the timing information is for all of the test. So exec time should be compared to a
sum of all the individual tests wall-clock times.
Web site
Even still in development, this web site can be used to look up the most important information. If you need an additional information that can be looked up from the db and is not available through the site let me know and I can give it to you directly. Please feel free to send me any comments, suggestions, feature requests.
